MASZYNKA ROBIĄCA BIPBIP BIP WEB SCRAPER
1. OVERVIEW
In Poland every local goverment is obliged to publish all documents, resolutions, ordinances etc. on the websites called Biuletyn Informacji Publicznej (BIP). Following all of them is pretty obnoxious, so I've decided to create web scrapers for some cities/towns around me. The results of daily scraping can be found here -> HERE. In this section, I will walk through the code of one of them - Rybnik.
2. PREREQUISITES
So we start coding with importing some libraries (all of them can be found in the
requirements.txt file):
Show/Hide code
1
2
3
import gspread, requests, urllib3, os, bs4
from oauth2client.service_account import ServiceAccountCredentials
from datetime import datetime
GSpread is a big library used to interact with Google Sheets.requests and urllib3 will be needed to make a connections with websites.bs4) is necessary to find elements on the website and scrape them.from oauth2client.service_account import ServiceAccountCredentials is necessary to access Google API.from datetime import datetime we will use to get the current time and date to provide users with date of
the latest update.os is important to get the current working directory to access API credentials sheet.To be able to re-create this script, you have to set your Google API beforehand (please see GSpread documentation).
3. CODE ANALYSIS
Once we have imported all of the modules, we have to set up Google API connection:
Show/Hide code
1
2
3
4
5
6
7
8
9
10
11
12
13
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
path = os.getcwd()
credentials_path = os.path.join(path, "credentials_file_name")
creds = ServiceAccountCredentials.from_json_keyfile_name(credentials_path, scopes = scopes)
file = gspread.authorize(creds)
workbook = file.open_by_key('XXXXXX WORKBOOK KEY XXXXXXX')
sheet = workbook.worksheet('WORKSHEET NAME')
Then we proceed with scraping:
Show/Hide code
1
2
3
4
5
6
7
8
9
rbk_res_o = requests.get("https://bip.um.rybnik.eu/Default.aspx?Page=31")
rbk_res_o.raise_for_status()
print("-----------------------------------------")
print("Połączono z ogłoszeniami urzędowymi.")
rbk_soup_o = bs4.BeautifulSoup(rbk_res_o.text, "html.parser")
rbk_date_o = []
rbk_date_o_all = rbk_soup_o.find_all("td", class_="text-nowrap text-center") # Wyszukiwanie dat ogłoszeń
for item in rbk_date_o_all:
rbk_date_o.append(item.text)
https://bip.um.rybnik.eu/Default.aspx?Page=31.
Once the connection is established successfully (line 2), we send a message to the user (line number 4).
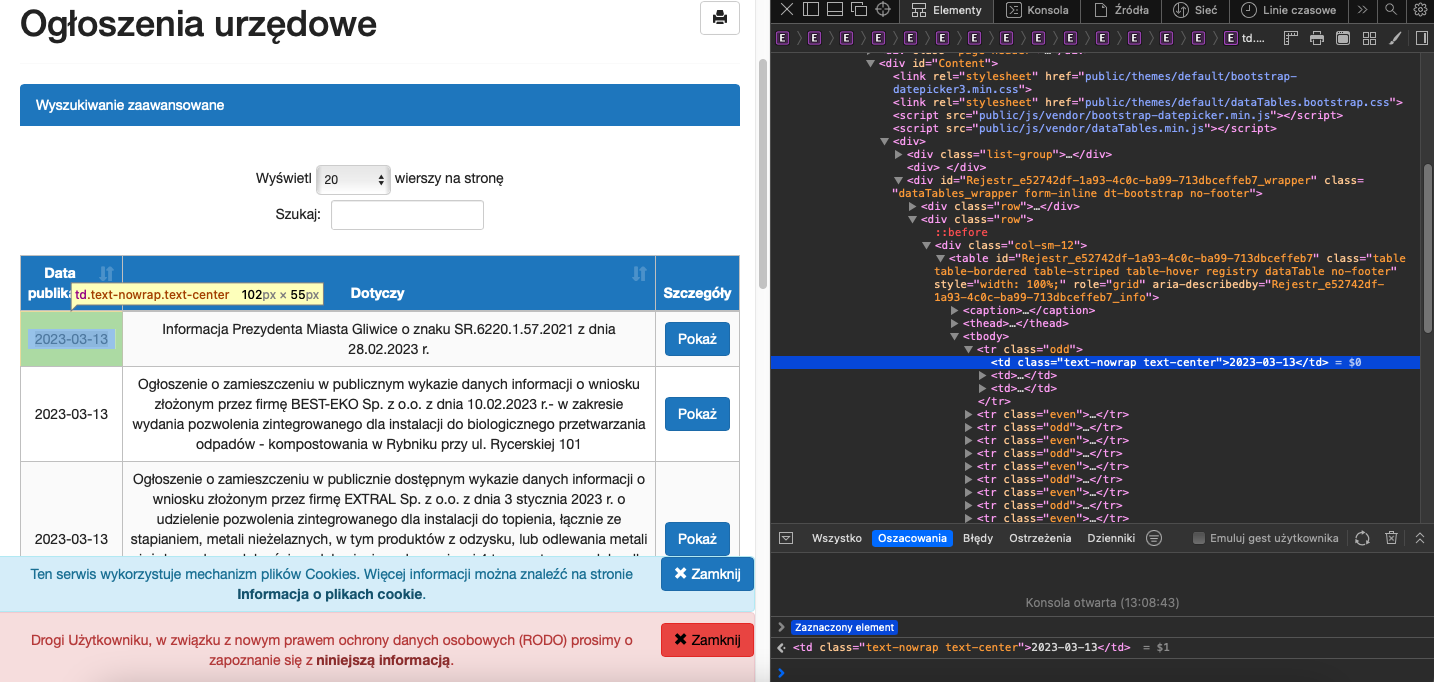
On the line number 5, we retrieve the whole webpage as a BeautifulSoup element. And after webpage source code inspection,
we search for all td elements with class attribute set to
"text-nowrap text-center", as those elements contain the documents dates (see screenshot below). Then we added
all retrieved elements to the rbk_date_o list using a loop and .text method
(to get rid of the html).
We a list with the dates is filled, we check if the date of the last updated document (which is located in cell "A4") is older than last document found online. If yes, then we send a message to the user that there are new documents found and we proceed with the script, if no, we send a message to the user that there are no new documents.
Show/Hide code
1 2 3 4 5 6 7 8 | #Jeśli najnowsza data w arkuszu i w BIPie jes ta sama, oznacza to brak nowych ogłoszeń i można przejsć dalej. if sheet.acell('A4').value == rbk_date_o_all[0].text: print("Brak nowych ogłoszeń urzędowych!") # Jeśli znaleziono nowe ogłoszenia, skrypt się uruchamia. else: print("Znaleziono nowe ogłoszenia urzędowe w Rybniku.") |
Next steps are to retrieve announcments bodies and URLs. To do so, we search for all buttons with
class
attribute set to "btn btn-primary". Then we get a value from all retrieved elements
["href"]
and add to every retrieved element the URL prefix
https://bip.um.rybnik.eu/. Last step is to append all URLs to a list rbk_urls_o.
To get all the announcements bodies, we go back to the dates soup (rbk_date_o_all = rbk_soup_o.find_all("td", class_="text-nowrap text-center"))
and we get a sibling for every element found (we narrow the number of dates to 50). And then we add
every sibling to a list rbk_body_o.
Show/Hide code
1 2 3 4 5 6 7 8 9 | rbk_url_o = rbk_soup_o.find_all("a", class_="btn btn-primary") # Wyszukiwanie linków do ogłoszeniach rbk_url_pre_o = "https://bip.um.rybnik.eu/" rbk_urls_o = [] for url in rbk_url_o: rbk_url_post = rbk_url_pre_o+url.get("href") rbk_urls_o.append(rbk_url_post) # Wydobycie linków i wrzucenie ich do listy, z której zostaną wrzucone do arkusza rbk_body_o = [] for i in range(0, 50): rbk_body_o.append(rbk_date_o_all[i].nextSibling.nextSibling.text) # Wydobycie treści ogłoszeń i wrzucenie do listy |
At this point we have 3 list containing announcements' dates, bodies and URLs:
rbk_dates_orbk_body_orbk_urls_o.Show/Hide code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | print("Aktualizuję ogłoszenia urzędowe...") # Aktualizacja linków urls_cell_list_o = sheet.range("C4:C28") for j, cell in enumerate(urls_cell_list_o): cell.value = rbk_urls_o[j] sheet.update_cells(urls_cell_list_o) # Aktualizacja dat dates_cell_list_o = sheet.range("A4:A28") for j, cell in enumerate(dates_cell_list_o): cell.value = rbk_date_o[j] sheet.update_cells(dates_cell_list_o) # Aktualizacja treści body_cell_list_o = sheet.range("B4:B28") for j, cell in enumerate(body_cell_list_o): cell.value = rbk_body_o[j] sheet.update_cells(body_cell_list_o) print("Ogłoszenia urzędowe zostały zaktualizowane!\n") |
Last step of the script is to provide users with the hour/date of last update in the cell A1:
Show/Hide code
1 2 3 | now = datetime.now() date_time = now.strftime("%d/%m/%Y %H:%M:%S") sheet.update('A1', f"Ostatnia aktualizacja: {date_time}") |
We repeat all the steps for other documents on this website.
4. CODE
Complete code can be found below and on my
Github and below. On Github you can find also code
for other cities/towns.
Show/Hide complete code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
#!/usr/bin/python3
import gspread, requests, urllib3, os, bs4
from oauth2client.service_account import ServiceAccountCredentials
from datetime import datetime
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
path = os.getcwd()
credentials_path = os.path.join(path, "credentials_file_name")
creds = ServiceAccountCredentials.from_json_keyfile_name(credentials_path, scopes = scopes)
file = gspread.authorize(creds)
workbook = file.open_by_key('XXXXXX WORKBOOK KEY XXXXXXX')
sheet = workbook.worksheet('WORKSHEET NAME')
# Ogłoszenia urzędowe
rbk_res_o = requests.get("https://bip.um.rybnik.eu/Default.aspx?Page=31")
rbk_res_o.raise_for_status()
print("-----------------------------------------")
print("Połączono z ogłoszeniami urzędowymi.")
rbk_soup_o = bs4.BeautifulSoup(rbk_res_o.text, "html.parser")
rbk_date_o = []
rbk_date_o_all = rbk_soup_o.find_all("td", class_="text-nowrap text-center") # Wyszukiwanie dat ogłoszeń
for item in rbk_date_o_all:
rbk_date_o.append(item.text)
#Jeśli najnowsza data w arkuszu i w BIPie jes ta sama, oznacza to brak nowych ogłoszeń i można przejsć dalej.
if sheet.acell('A4').value == rbk_date_o_all[0].text:
print("Brak nowych ogłoszeń urzędowych!")
# Jeśli znaleziono nowe ogłoszenia, skrypt się uruchamia.
else:
print("Znaleziono nowe ogłoszenia urzędowe w Rybniku.")
rbk_url_o = rbk_soup_o.find_all("a", class_="btn btn-primary") # Wyszukiwanie linków do ogłoszeniach
rbk_url_pre_o = "https://bip.um.rybnik.eu/"
rbk_urls_o = []
for url in rbk_url_o:
rbk_url_post = rbk_url_pre_o+url.get("href")
rbk_urls_o.append(rbk_url_post) # Wydobycie linków i wrzucenie ich do listy, z której zostaną wrzucone do arkusza
rbk_body_o = []
for i in range(0, 50):
rbk_body_o.append(rbk_date_o_all[i].nextSibling.nextSibling.text) # Wydobycie treści ogłoszeń i wrzucenie do listy
print("Aktualizuję ogłoszenia urzędowe...")
# Aktualizacja linków
urls_cell_list_o = sheet.range("C4:C28")
for j, cell in enumerate(urls_cell_list_o):
cell.value = rbk_urls_o[j]
sheet.update_cells(urls_cell_list_o)
# Aktualizacja dat
dates_cell_list_o = sheet.range("A4:A28")
for j, cell in enumerate(dates_cell_list_o):
cell.value = rbk_date_o[j]
sheet.update_cells(dates_cell_list_o)
# Aktualizacja treści
body_cell_list_o = sheet.range("B4:B28")
for j, cell in enumerate(body_cell_list_o):
cell.value = rbk_body_o[j]
sheet.update_cells(body_cell_list_o)
print("Ogłoszenia urzędowe zostały zaktualizowane!\n")
print("-----------------------------------------")
# Zarządzenia prezydenta
rbk_res_p = requests.get("https://bip.um.rybnik.eu/Default.aspx?Page=214")
rbk_res_p.raise_for_status()
print("Połączono z zarządzeniami prezydenta.")
rbk_soup_p = bs4.BeautifulSoup(rbk_res_p.text, "html.parser")
rbk_date_p_all = rbk_soup_p.find_all("td", class_="text-nowrap text-center")
rbk_date_p = []
for item in rbk_date_p_all:
rbk_date_p.append(item.text)
if sheet.acell('E4').value == rbk_date_p[0]:
print("Brak nowych zarządzeń prezydenta!")
else:
table_body_p = rbk_soup_p.find_all("tbody")
rbk_url_p = rbk_soup_p.find_all("a", class_="btn btn-primary")
rbk_url_pre_p = "https://bip.um.rybnik.eu/"
rbk_urls_p = []
for url in rbk_url_p:
rbk_url_post_p = rbk_url_pre_p+url.get("href")
rbk_urls_p.append(rbk_url_post_p)
rbk_body_p = []
for i in range(0, 25):
rbk_body_p.append(rbk_date_p_all[i].previousSibling.previousSibling.text)
print("Aktualizuję zarządzenia prezydenta...")
# Aktualizacja linków
urls_cell_list_p = sheet.range("G4:G28")
for j, cell in enumerate(urls_cell_list_p):
cell.value = rbk_urls_p[j]
sheet.update_cells(urls_cell_list_p)
# Aktualizacja dat
dates_cell_list_p = sheet.range("E4:E28")
for j, cell in enumerate(dates_cell_list_p):
cell.value = rbk_date_p[j]
sheet.update_cells(dates_cell_list_p)
# Aktualizacja treści
body_cell_list_p = sheet.range("F4:F28")
for j, cell in enumerate(body_cell_list_p):
cell.value = rbk_body_p[j]
sheet.update_cells(body_cell_list_p)
print("Zarządzenia prezydenta zostały zaktualizowane!")
print("-----------------------------------------")
# Uchwały RM
rbk_res_rm = requests.get("https://bip.um.rybnik.eu/Default.aspx?Page=247")
rbk_res_rm.raise_for_status()
print("Połączono z uchwałami rady miasta.")
rbk_soup_rm = bs4.BeautifulSoup(rbk_res_rm.text, "html.parser")
rbk_date_rm_all = rbk_soup_rm.find_all("td", class_="text-nowrap text-center")
rbk_date_rm = []
for item in rbk_date_rm_all:
rbk_date_rm.append(item.text)
if sheet.acell('A32').value == rbk_date_rm[0]:
print("Brak nowych uchwał rady miasta!\n")
else:
rbk_url_rm = rbk_soup_rm.find_all("a", class_="btn btn-primary")
rbk_url_pre_rm = "https://bip.um.rybnik.eu/"
rbk_urls_rm = []
for url in rbk_url_rm:
rbk_url_post_rm = rbk_url_pre_rm+url.get("href")
rbk_urls_rm.append(rbk_url_post_rm)
rbk_body_rm = []
for i in range(0, 50):
rbk_body_rm.append(rbk_date_rm_all[i].nextSibling.nextSibling.text)
print("Aktualizuję uchwały rady miasta...") # Aktualizacja uchwał w arkuszu
# Aktualizacja linków
urls_cell_list_rm = sheet.range("C32:C56")
for j, cell in enumerate(urls_cell_list_rm):
cell.value = rbk_urls_rm[j]
sheet.update_cells(urls_cell_list_rm)
# Aktualizacja dat
dates_cell_list_p = sheet.range("A32:A56")
for j, cell in enumerate(dates_cell_list_p):
cell.value = rbk_date_rm[j]
sheet.update_cells(dates_cell_list_p)
# Aktualizacja treści
body_cell_list_rm = sheet.range("B32:B56")
for j, cell in enumerate(body_cell_list_rm):
cell.value = rbk_body_rm[j]
sheet.update_cells(body_cell_list_rm)
print("Uchwały rady miasta zostały zaktualizowane.")
now = datetime.now()
date_time = now.strftime("%d/%m/%Y %H:%M:%S")
sheet.update('A1', f"Ostatnia aktualizacja: {date_time}")